


Tekstherkenning met Linux
Er zijn verschillende tekstherkenning programma's onder Linux.
Dit zijn allen commandline programma's.
Gelukkig is er ook een grafische schil beschikbaar die in de achtergrond gebruik maakt van die ocr programma's zonder dat wij die ocr programma's moeten kennen.
OCRFeeder bestaat zowel voor Linux als voor Windows. Het zou me dus verwonderen dat het niet in jouw software installatie programma staat.
Als eerste werk moet je dit programma dus installeren.
Verder heb je dus ook een goed ocr programma nodig. Er zijn er verschillende verkrijgbaar onder Linux.
Na wat uitproberen, is volgens mij tesseract veruit de beste. Je installeert deze dus ook samen met de taalfile voor de taal die je wilt kunnen omzetten.
Tesseract-ocr en ook tesseract-ocr-nld voor het Nederlands.
Genoeg verteld, nu aan de slag.
Open Xsane of een ander scanprogramma dat in grijstinten kan scannen. (vb: simplescan doet dit niet)
Scan uw document in grijstinten met 600dpi en sla dit op.
Neem voor deze eerste kennismaking een blad zonder opmaak of afbeeldingen.
Open nu OCRFeeder
 |
Zo eenvoudig ziet het startscherm eruit. |
Klik nu op het groen
 kruis links boven en ga op zoek naar de ingescande tekst.
kruis links boven en ga op zoek naar de ingescande tekst.OCRFeeder ziet er nu al iets anders uit.
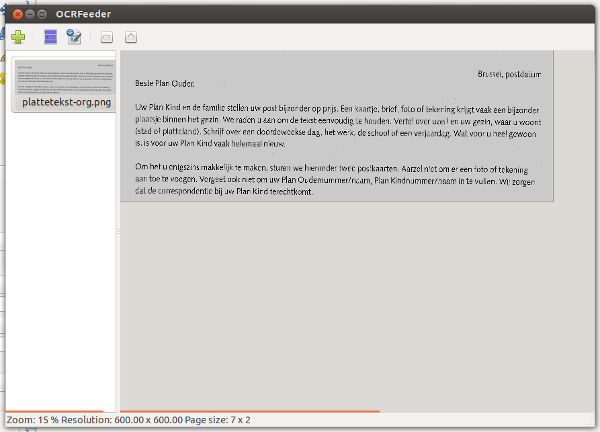 |
Links zie je de gescande afbeeldingen staan. Dat kunnen er meerdere zijn. Het groter venster geeft de geselecteerde afbeelding weer en hierop gebeuren alle bewerkingen. |
 |
Alle icoontje zijn nu opgelicht. Van links naar rechts zijn dat
|
De rechtse afbeelding verklein je met het witte minteken tot je ze volledig in je scherm ziet.
Klik dan met de linker muistoets in de linkerbovenhoek van je afbeelding en sleep je aanwijzer naar rechts onder tot de hele tekst geselecteerd is. In het vervolg zeg ik gewoon selecteer tekstblok.
Je krijg nu de volgende situatie.
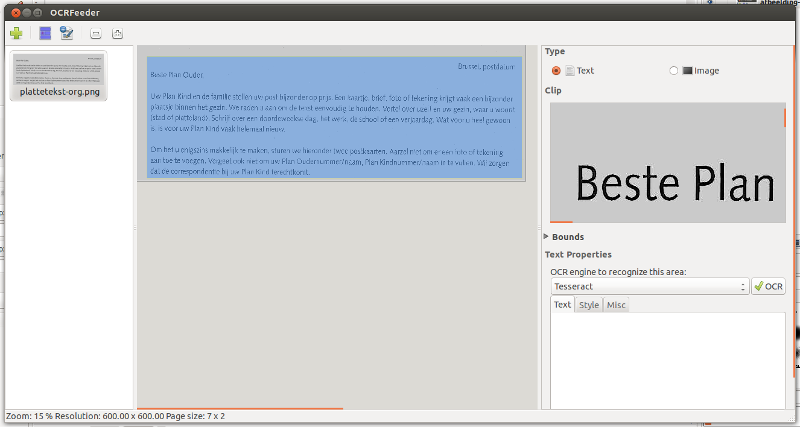 |
De geselecteerd tekst is met blauwe achtergrond geworden. En er is een derde vak bijgekomen. In dit derde vak gebeurd de eigenlijke tekstherkenning. |
Dit nieuwe vak ga ik nu uitgebreid bespreken want daar gebeurd alles.
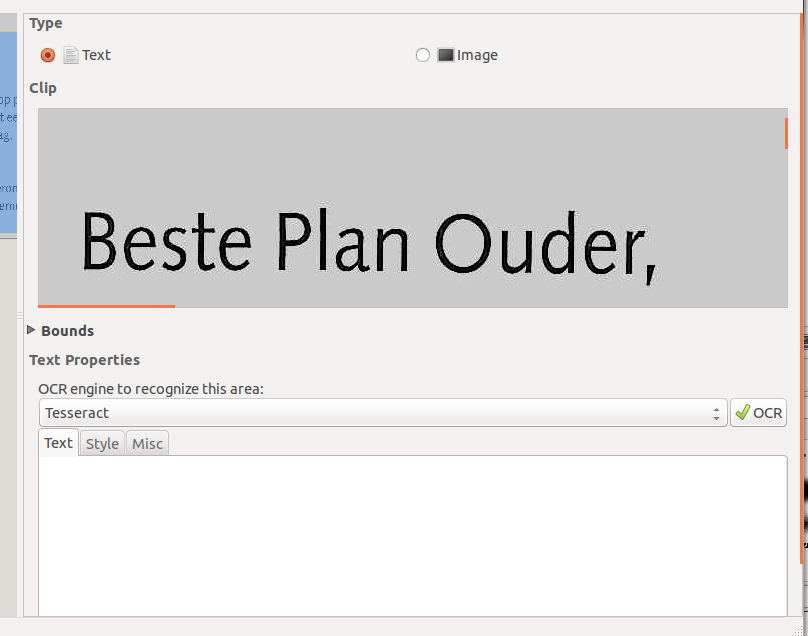 |
Links bovenaan zie je tekst staan, laat dit aangevinkt want je keuze was wel degelijk tekst. Als het een foto was dan kies je image, maar dat is voor later. Dan het grijze vak waar Beste Plan Ouder, staat is een voorbeeld van de geselecteerde blok in het nu middelste vak. Je kan meer selecties maken, maar ook dit is voor later. Dan zie je Bounds staan, hier kan je de exacte plaatsbepaling van je selectie mee aanpassen, maar ook dit is weer voor later. |
Vervolgens komen we aan Text Properties.
Onder OCR engine to recognize this area zie je bij mij Tesseract staan, mogelijk staat dit bij jou nog op gocr.
Verander dit dan in Tesseract.
Vervolgens klik je op OCR
En je krijgt dit als resultaat.
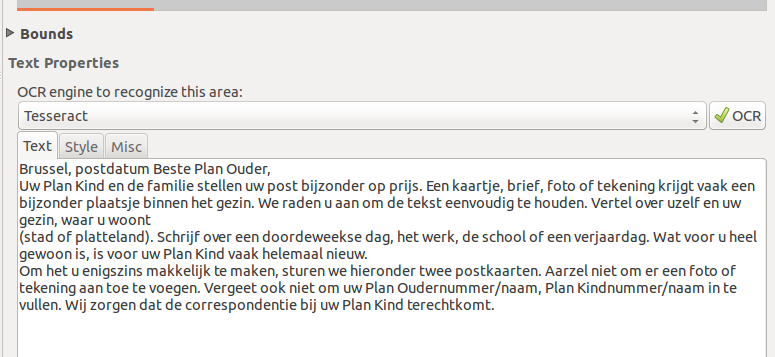 |
Zoals je hier kunt zien is dit voor 100% gelukt. Je bent in dit voorbeeld wel je opmaak verloren, maar dit kan anders en is ook weer voor later. |
Klik nu zeker nog op het tabblad Style.
 |
Het is een standaard blaadje met de uitlijning links, dus Align staat hier juist. Spacing dient om afwijkende spatiëring tussen letters en lijnen aan te passen, maar dat zal niet veel voorvallen en is enkel noodzakelijk als je een exacte kopie van je origineel wilt, en dit kan achteraf in LibreOffice eenvoudiger. |
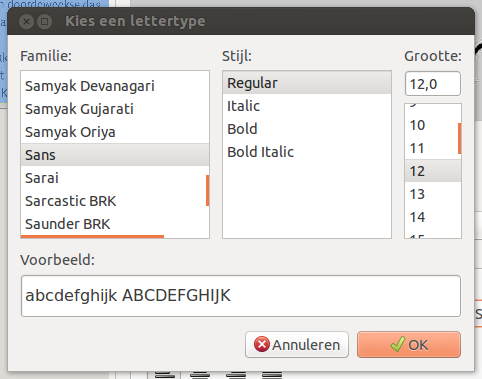 |
Onder Familie kan je hier kiezen uit 1 van de op je computer geïnstalleerde letters. Interessanter is de keuze stijl en Grootte. Voor grootte kies ik altijd voor 8. Dit is wat klein, maar achteraf in LibreOffice sneller aan te passen dan wanneer je een te grote grootte kiest. |
Rest je nog enkel om bovenaan op het middelste icoontje (exporteren als .odt) te klikken, en alles op te slaan.
Tenslotte hier een screenshot van bovenstaande uitleg in LibreOffice ingeladen.
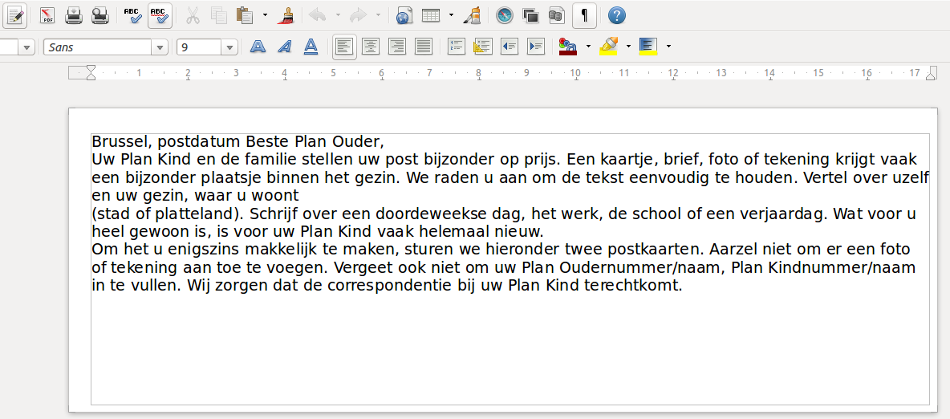
Hier is geen letter, punt of wat dan ook aan veranderd, dus Linux kan zeer goed aan tekst herkenning doen.
OCRFeeder, lay-out overnemen.
Het kan aan mij liggen, maar om met afbeeldingen te werken lukt het mij enkel in grijstinten.
Het overnemen van de lay-out gaat echter zoals men beloofd.
Ik ga toch kleur gebruiken en heb de afbeeldingen apart gescand, bij het maken van de lay-out wordt er ruimte voorzien.
 |
De bovenst rode en groen balk bezie ik als afbeelding. Selecteer hem in OCRFeed. |
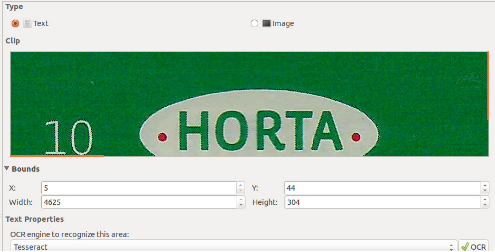 |
Je laat dit op Text staan, als je in grijs scant kan je het aanduiden als Image. Klik dan op Bounds. Daar de balk de volledige breedte van de folder is, heb ik x zo laag mogelijk gemaakt. Waarom dat geen 0 is maar 5 weet ik ook niet. Width heb ik zo groot mogelijk gepakt. Y en Height laat ik zoals ze zijn. Klik nu ZEKER NIET op OCR Op die manier wordt er enkel ruimte gemaakt in de lay-out. |
Vervolgens selecteer ik de afbeelding met het bijenhotel op de paal.
Waarom eerste deze afbeelding? Dan heb ik de y positie waar de bovenkant van de afbeelding staat en die heb ik nodig voor het tekstblok daar links naast.
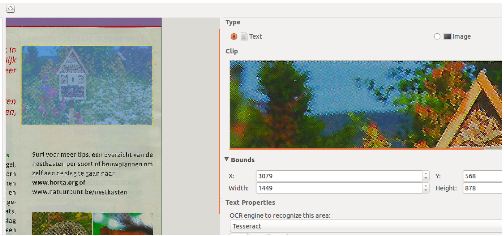 |
Onder bounds zie ik hier bij de y waarde 568 staan, dit schrijf ik even op. Zoals hierboven, op text laten staan en niet op ocr klikken. PS: om goed te kunnen selecteren heb ik op het plus icoontje geklikt om de afbeelding te vergroten. |
Nu selecteer ik de rode tekstblok.
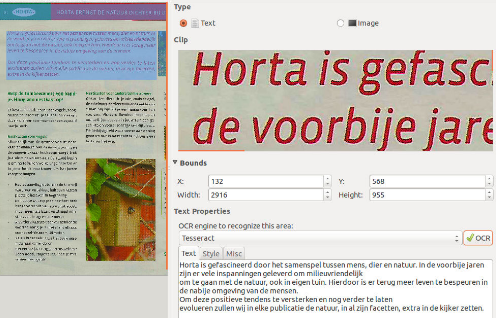 |
Let er bij het selecteren wel op dat je geen andere selectie raakt, want dan verdwijnt die. Hier zet ik y op dezelfde waarde als de afbeelding dus 568. Onthoud nu wel de x waarde en de breedte van deze selectie. Bij de volgende selecties daaronder kan je die dan op dezelfde waarde zetten. Dit is belangrijk om een juiste lay-out te hebben in LibreOffice. Ik onthou dus 132 en 2916. De linker kolommen beginnen dus op 132px van de linkerkant en de middelste kolom eindigt op 2916px van de linkerkant. |
De linker kolom neem ik in 1 maal, je kan dat in LibreOffice aanpassen. Zet hier de x coördinaat op 132 en onthoud de y coördinaat voor de kolom daar rechts naast.
Dan de middelste kolom, selecteer hier enkel de tekst, en zet de y coördinaat op die van de linkse kolom dus 1699.
Vergeet bij je tekstkolommen niet om op de ocr knop te klikken en onder style de font groote op 8 of 9 te zetten.
Nu selecteer je de afbeelding met het bijenhotel aan de muur, en kies weer voor text zonder op de ocr knop te klikken.
Nu rest nog enkel de rechter kolom.
Je kan dit in een keer selecteren, en in LibreOffice ruimte maken en de afbeeldingen toevoegen.
Ik ga het in 4 keer doen, dan staan de afbeeldingen exact op hun plaats. Dit gebeurd zoals bij de vorige delen.
Het eindresultaat ziet er nu zo uit.
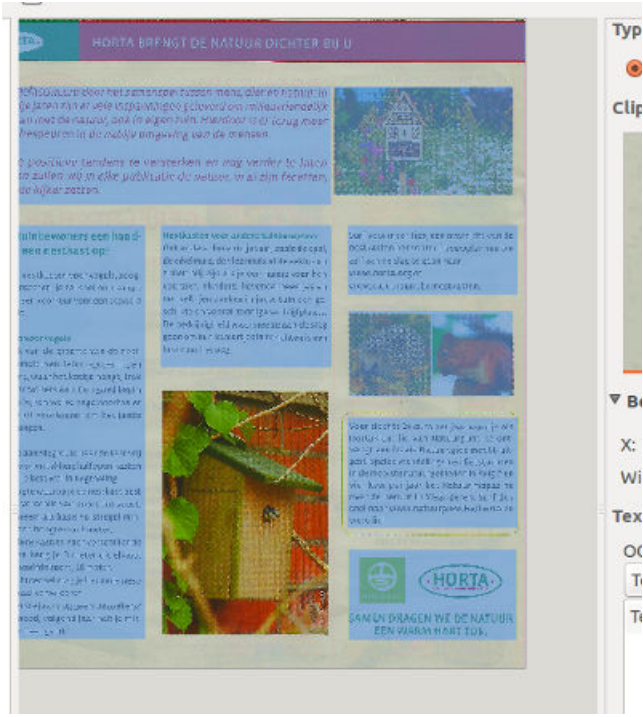
Nu kan je op het icoontje exporteren naar odt klikken en dan heb je hier in OCRFeeder gedaan met werken.
Nu naar LibreOffice.
Daar hebben we op dit ogenblik dit als resultaat.

De lay-out is er, nu nog wat aanpassen en de afbeeldingen plaatsen. En dan mag het resultaat er volgens mij wel zijn.
Een bijdrage van hugosu.
Terug naar het menu